Title:
BLENS: Biomedical Literature Extraction & Scoring System
Poster
Preview Converted Images may contain errors
Abstract
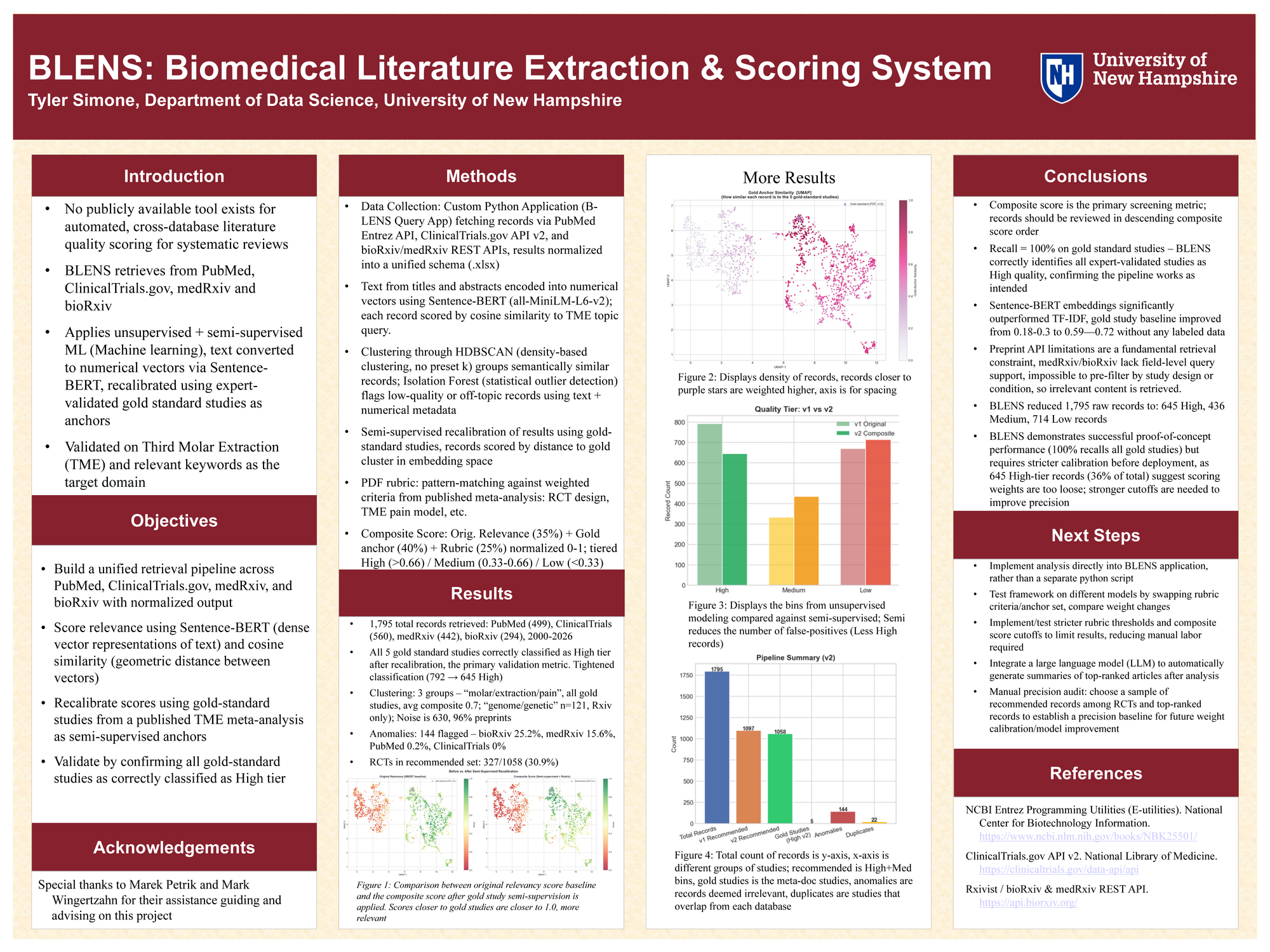
Systematic reviews require comprehensive retrieval across multiple databases, yet no publicly available tool exists for automated cross-database literature quality scoring. BLENS retrieves records from PubMed, ClinicalTrials.gov, medRxiv, and bioRxiv, scoring all output via a ML pipeline validated on Third Molar Extraction (TME) literature and keywords.
Text is encoded into dense vectors using Sentence-BERT and scored by cosine similarity to a domain-specific query. A semi-supervised anchoring layer uses 5 expert-validated gold-standard studies as labeled seeds to recalibrate scores across all records. A rubric then scores against 5 weighted inclusion criteria gathered from a published TME meta-analysis, combining these scores into three bins tiered High, Medium, or Low.
Applied to 1,795 records, Blens achieves 100% recall on gold-standard studies, with composite scores improving from 0.59-0.72 at baseline to 0.80-0.99 after anchoring. HDBSCAN clustering independently confirmed results, separating preprints into off-topic clusters due to a vague retrieval from a weak API. Anomaly rates of 25% (bioRxiv) and 15.6% (medRxiv) versus 0.8% (PubMed) and 0% (ClinicalTrials) reflects the poor retrieval of preprints due to API query limits. BLENS is a proof of concept, where precision measurement via manual audit of top-rank records is the next critical step.
Authors
| First Name |
Last Name |
|
Tyler
|
Simone
|
Advisors:
| Full Name |
|
Marek Petrik
|
|
Matthew Magnusson
|
Leave a comment
Submission Details
Conference URC
Event Interdisciplinary Science and Engineering (ISE)
Department Computer Science (ISE)
Group Computer Science - Independent Projects
Added April 20, 2026, 7:25 p.m.
Updated April 20, 2026, 7:25 p.m.
See More Department Presentations Here